



Muitas áreas e indústrias estão concentrando esforços e recursos na incorporação de Inteligência Artificial e Aprendizado de Máquina em seus processos produtivos. Esses termos parecem atrair a atenção de todos, mas será que realmente entendemos suas vantagens e limitações?
O conceito de Machine Learning (também conhecido como aprendizado de máquina) refere-se à ideia de que as máquinas podem "aprender", a partir de dados de treinamento, a realizar tarefas que geralmente são feitas por humanos, como reconhecer padrões ou classificar objetos em diferentes categorias. Por outro lado, a Inteligência Artificial é um conceito mais amplo, que exige que as máquinas sejam capazes de realizar tarefas de forma "inteligente".
Essa é uma das aplicações da inteligência artificial e possui dois núcleos fundamentais: de um lado, existem a programação e a capacidade computacional; e de outro, a análise matemática e estatística. O trabalho conjunto dessas duas frentes faz com que o aprendizado de máquina funcione bem e, se uma dessas frentes falhar, os algoritmos de ML não funcionarão corretamente.
As vantagens de aplicar o Aprendizado de Máquina são óbvias, pois permite automatizar tarefas muitas vezes tediosas e também aumenta a eficiência, uma vez que um computador possui uma velocidade de cálculo muito superior à de um ser humano.
Porém, implementar o Aprendizado de Máquina por si só muitas vezes não é suficiente, principalmente quando se trata de tarefas de grande complexidade, pois as máquinas carecem da intuição e da experiência que um profissional competente na área de trabalho pode ter. É aqui que entra o conceito de ciência de dados:
Data science é um campo interdisciplinar, que envolve diferentes áreas do conhecimento e da tecnologia para extrair ou melhorar a compreensão dos dados de que dispomos. A ciência de dados tem três pilares fundamentais: programação de computadores, análise estatística e especialização setorial. Como pode ser visto, os dois primeiros correspondem aos núcleos do Machine Learning mencionados acima; Na verdade, é muito comum que quando se fala em ciência de dados um diagrama de Venn seja apresentado com seus três pilares (cujos nomes podem variar de acordo com o autor, mas a ideia permanece), e o ML esteja localizado na intersecção entre os dois primeiros.
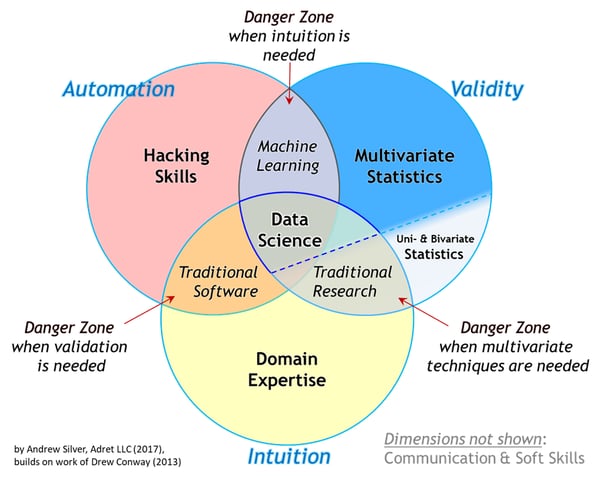
(The Essential Data Science Venn Diagram | by Andrew Silver | Towards Data Science)
Mas a ciência de dados adiciona uma nova dimensão: a especialização do setor. Refere-se ao conhecimento que as pessoas possuem sobre a área em que atuam, e é fundamental quando se deseja aplicar o ML em qualquer setor, seja ele econômico, na saúde ou na manutenção. É necessário que as pessoas que projetam e implementam algoritmos de Aprendizado de Máquina tenham conhecimento da área em que desejam utilizá-los e saber quais dados são relevantes para alimentar os modelos, quais algoritmos são os mais adequados para modelar o que é necessário compreender e também saber quais resultados esperar desses algoritmos, para que você possa discernir se seu aplicativo está funcionando corretamente ou não.
Com Predictto nós damos importância aos três pilares da ciência de dados, para que possamos garantir que nossos algoritmos funcionem, e que funcionem bem! Uma vez que foram projetados tendo em mente a otimização da manutenção de seus ativos.
Você não precisa ser um cientista de dados para entendê-los, pois cuidamos do rigor e damos a você insights simplificados, bem como todas as ferramentas necessárias para que você possa interpretá-los.

Prepare-se para o lançamento do Predictto com o curso: IoT e manutenção preditiva. Aprenda de forma simples cada um dos aspectos básicos desta nova era da manutenção 4.0Acesse o link: https://fracttal-br.teachable.com/p/iot-preditiva